Occlusion-Robust Cross-Modal 3D Human Pose Estimation via Adaptive RGB-D Fusion and Hierarchical Graph Reasoning
DOI:
https://doi.org/10.64972/jaat.2024v2.254p10e:138-148Keywords:
Cross-Modal Learning, 3D Pose Estimation, Graph Convolutional Networks, Occlusion RobustnessAbstract
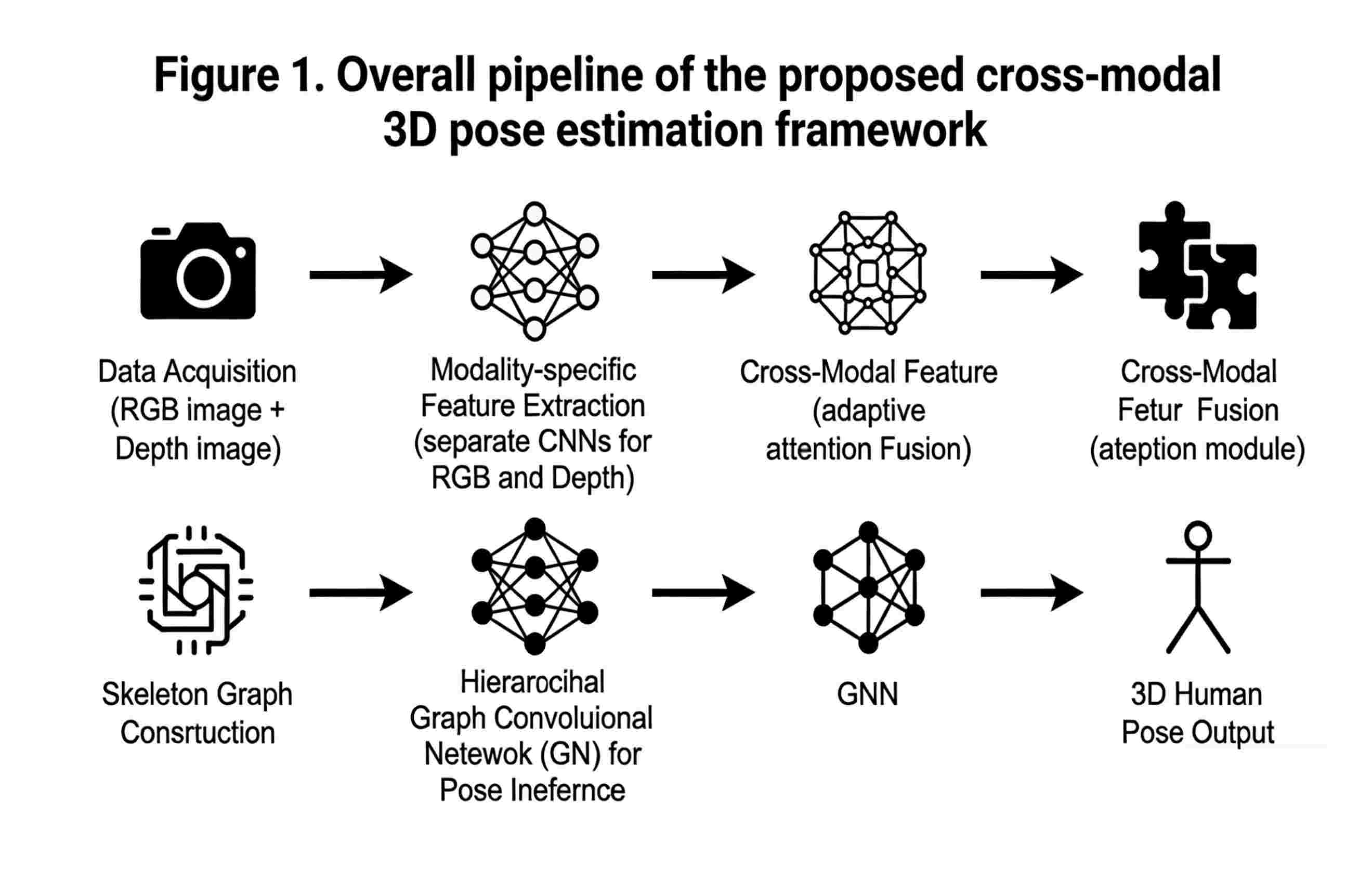
Three-dimensional (3D) human pose estimation is crucial for intelligent systems involved in human–computer interaction, motion analysis, and clinical assessment, yet existing deep learning models struggle with occlusion, sensor noise, and perceptual limitations in single-modal settings. To address these issues, we propose a unified cross-modal 3D pose estimation framework that integrates RGB and depth data through a novel adaptive fusion module, selectively combining key features from both modalities at the intermediate stage to preserve complementary information. The fused features are represented as a skeleton map and processed by a hierarchical graph convolutional network, effectively capturing both local and global structural dependencies. Extensive experiments on the Human3.6M and MSRA datasets validate the effectiveness of our approach: the proposed method achieves a mean per-joint position error (MPJPE) of 27.6 mm on Human3.6M, substantially outperforming the single-modal baseline (34.1 mm) and previous cross-modal methods (30.8 mm), while the Percentage of Correct Keypoints (PCK) at 50 mm reaches 94.5%. These results demonstrate that the proposed framework significantly improves estimation accuracy and robustness under occlusion and noisy input, while maintaining high inference efficiency and manageable model complexity. Our findings highlight the importance of joint multimodal fusion and hierarchical structural reasoning for advancing robust, scalable 3D pose perception in unconstrained environments.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 İlknur Mağden, Gülcan Kahraman, Nuran Şahbaz

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





