Camera-LiDAR Sensor Fusion Transformer for Robust Real-Time Semantic Segmentation in Autonomous Driving Scenes
DOI:
https://doi.org/10.64972/jaat.2024v2.251p7e:88-100Keywords:
Semantic Segmentation, Autonomous Vehicles, LiDAR, Scene Understanding, Real-Time ProcessingAbstract
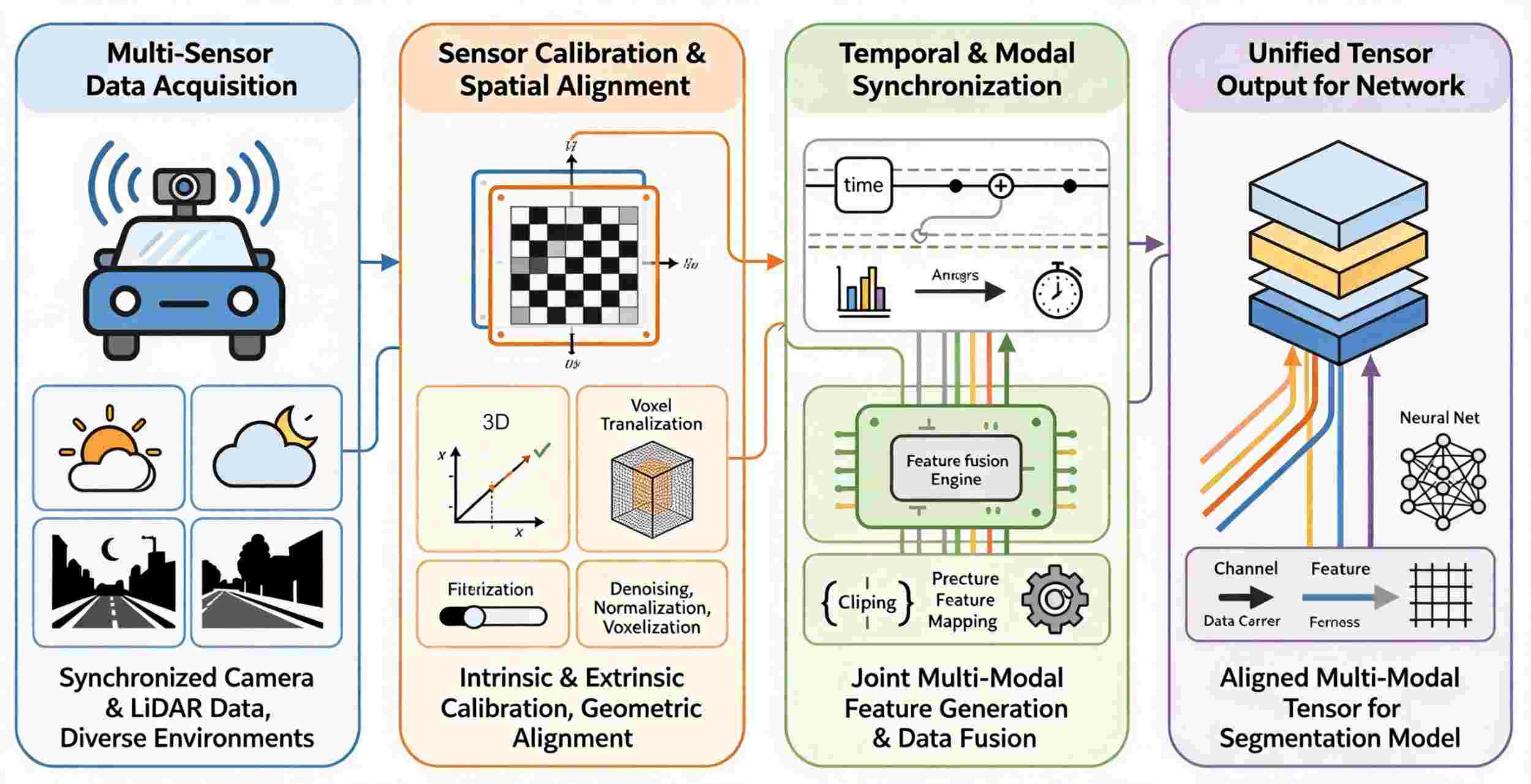
Perform semantic segmentation on complex road scenes to achieve more reliable autonomous vehicle operation. This paper proposes a multimodal segmentation framework that integrates RGB camera and LiDAR data through a hybrid integration strategy and a transformer-based network architecture. Many large-scale benchmark experiments have been conducted to cover various scenarios with different lighting conditions, weather, and traffic densities, such as SemanticKITTI and nuScenes. The mIoU for the "car" category is 81%, and it surpasses the current best models by 5-10 percentage points in the more challenging categories of "pedestrian" and "motorcycle." In terms of real-time performance, the inference speed is 29.5 frames per second, with a peak memory usage of 3.2 GB. Ablation studies indicate that the mid-term hybrid fusion model is better; RGB + LiDAR input improves mIoU by over 4% compared to unimodal methods. According to user research, the quality rating for this section is 4.6/5 or higher. Based on the above results, we believe that this system will perform well and have practical value in future intelligent transportation systems.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Hrvoj Kovačev, Lovro Žugaj, Valentina Živković

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





