A Lightweight Distilled RoBERTa Framework for High-Performance Technical Keyword Extraction
DOI:
https://doi.org/10.64972/jaat.2025v3.215p27e:362-375Keywords:
Swarm Intelligence, Domain Adaptation, Knowledge Distillation, Keyword ExtractionAbstract
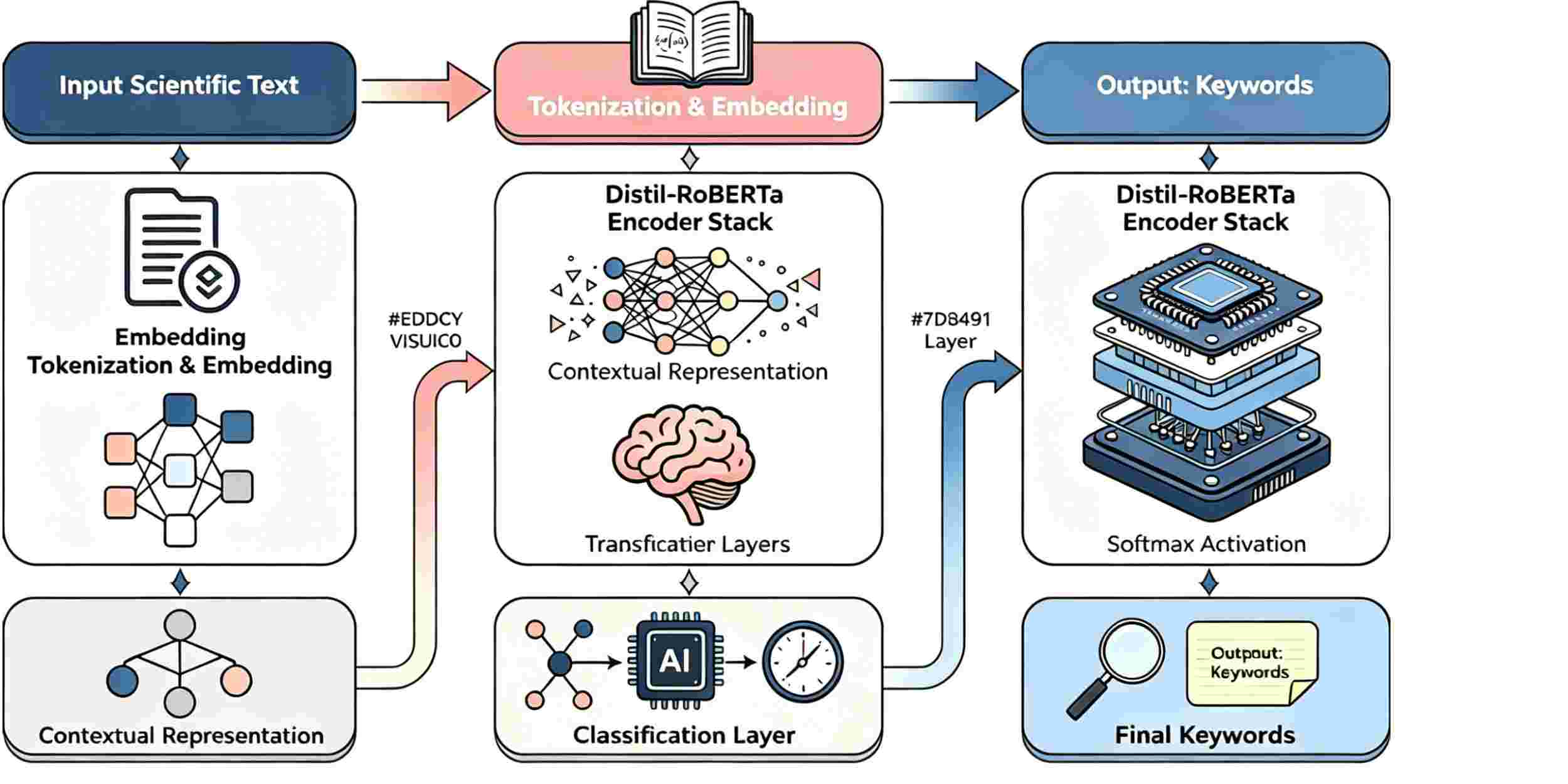
Many are now being extracted from scientific publications to increase the effectiveness of content organization and information retrieval for knowledge-based services in science. Here, a lightweight framework based on knowledge-distilled RoBERTa is developed to handle the challenge of concurrently obtaining high extraction accuracy and resource efficiency. By employing effective pre-training techniques and unique loss functions, you may transfer semantically and contextually rich data from a powerful teacher model to a tiny student network while maintaining language sensitivity and minimising model size. Numerous cross-domain datasets containing over 7,600 full-text papers in the fields of science, life, and medicine, as well as materials, have been made available for assessment. In comparison to normal RoBERTa, the distilled model cut the training time by a factor of 3.7 and attained a mean F1-score of 0.851, outperforming both the traditional baseline and other lightweight models, according to the experiment mentioned above. Ablation analysis reveals that optimal performance is attained when the encoder and attention mechanism setup are at the appropriate depth. Additionally, visualisation demonstrates that the model can identify the same domain words from various document sections without sacrificing performance. In general, this approach can be used to achieve high-performance, large-scale keyword extraction from vast research libraries and add models for specific adaption.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Maksymilian Mędrek

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





