Vision-Based Grasping for Industrial Robots Guided by Deep Q-Networks
DOI:
https://doi.org/10.64972/jaat.2026v4.123p166-178Keywords:
Visual Perception, Deep Reinforcement Learning, Robotic Grasping, DQN, Industrial Automation, Sim-to-Real Transfer, Multi-Modal Perception, Manipulation RoboticsAbstract
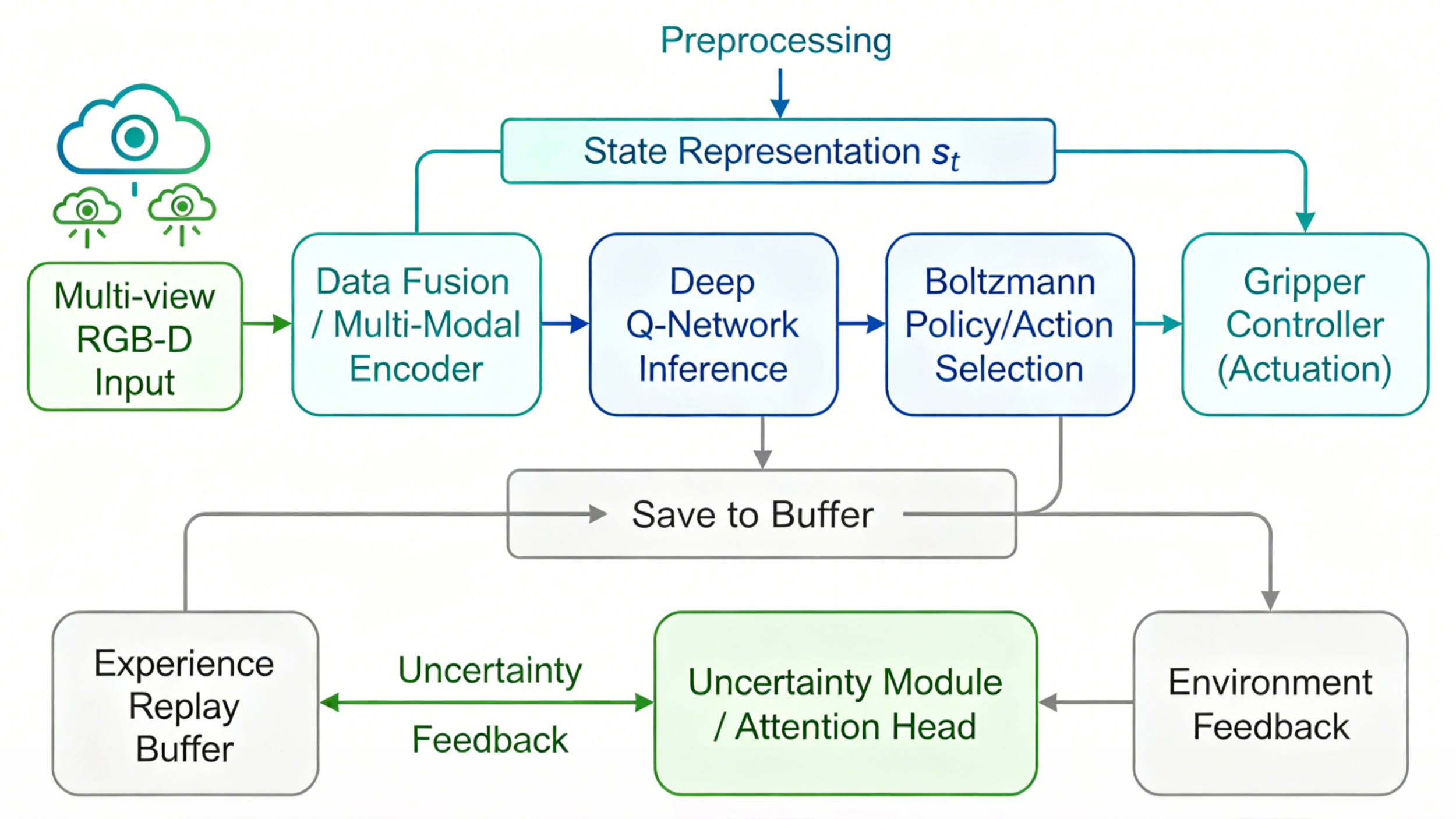
This paper proposes a vision-to-grasp framework driven by a Deep Q-Network (DQN). The framework is designed for industrial robots in complex and dynamic factory environments. Multimodal visual perception, robust scene understanding, and adaptive deep reinforcement learning-based grasp planning are the three components of the new framework. The experiments were conducted in both simulated and real environments, using a UR5e robotic arm equipped with an RGB-D camera and a standard industrial gripper. In the 200,000 training steps in the simulation, the asymptotic grasping success rate of the Double DQN variant was 93.4%, which is 6.2 %age points higher than the standard DQN, and the reward variance was reduced by over 38%. Boltzmann's study achieved a success rate of 92.8% within 80,000 steps, far surpassing the noise network and ε-greedy methods. The framework achieved a success rate of over 90% for grasping both simple and complex objects on physical hardware, with success rates of 95.1%, 91.3%, and 87.6% for acrylic boxes and ceramic cups, respectively. In mixed and cluttered environments, the system achieved a total success rate of 92.5% over 300 rounds, with a relatively short grasp execution time of 2.7 to 3.7 seconds. Robustness tests indicate that it can generalize well to new objects, partial occlusions, and lighting changes. Failure analysis pointed out the main defects in spatial alignment and reflection. The above results indicate that DQN-based visual-guided grasping has been applied in practice and is feasible in industrial environments.
Downloads
Published
Versions
- 2026-05-14 (2)
- 2026-03-16 (1)
How to Cite
Issue
Section
License
Copyright (c) 2026 Emilia Zdzisława Dąbrowska, Karolina Alicja Bąk, Paweł Jankowski, Aleksandra Król

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





