Adaptive Honeypot Deployment in Software-Defined Networks Based on Deep Q-Learning
DOI:
https://doi.org/10.64972/jaat.2026v4.145p23e:303-316Abstract
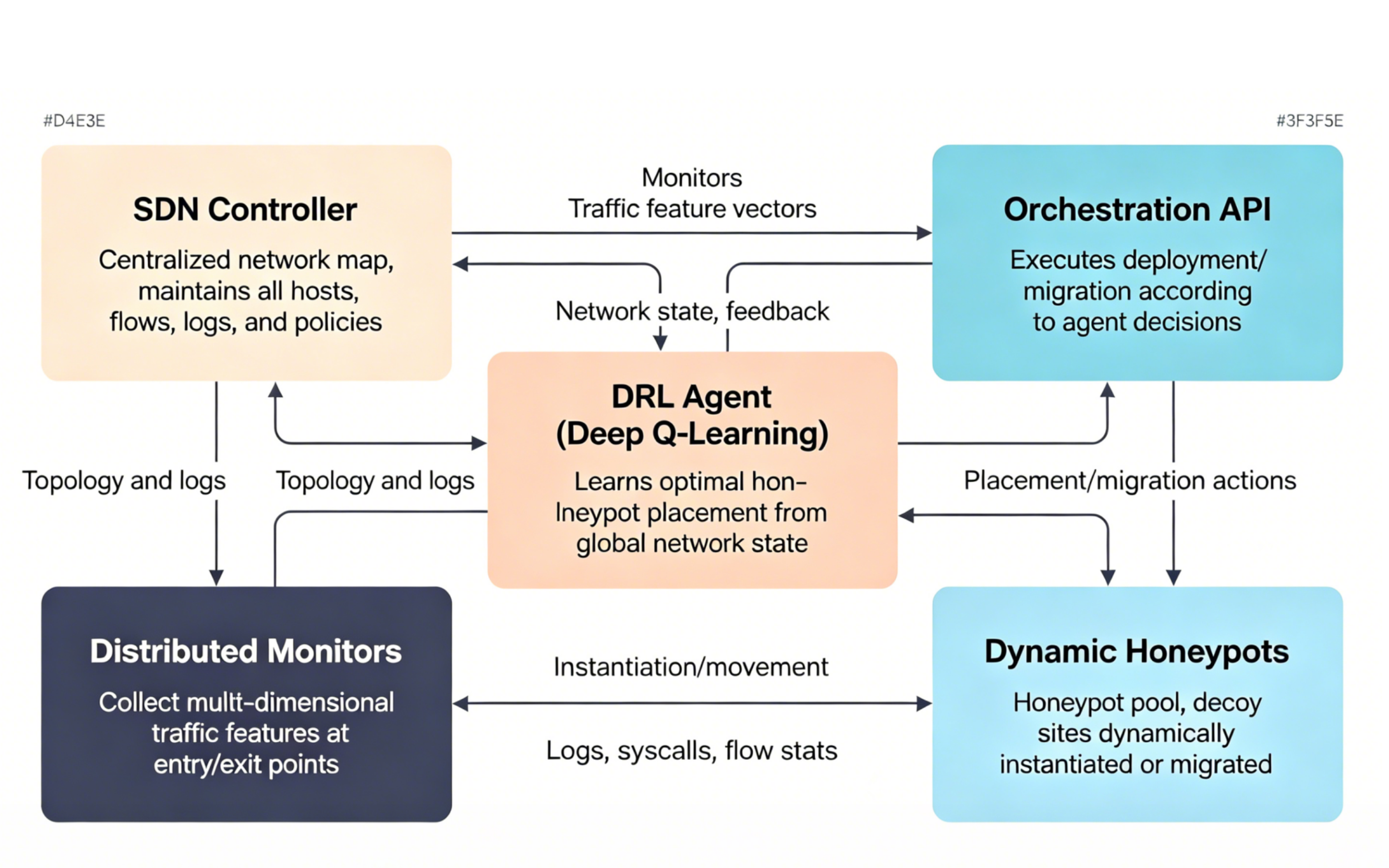
The conventional deployment approach for static honeypots is no longer appropriate, and their detection performance and resource utilization have declined in modern network defense as software-defined networks (SDN) have progressively grown more complex and dynamic. In order to enable intelligent, context-aware cyber deception, this study presents an adaptive honeypot orchestration architecture that combines SDN programmability and deep Q-learning reinforcement learning. A deep Q-network agent dynamically adjusts decoy sites based on observed adversarial behavior and the real-time network status. The general form of the core methodology is a high-dimensional Markov decision process for honeypot deployment. The aforementioned technique can increase the average detection rate to 0.85 and improve it by almost 20% when compared to that attained by static and periodic techniques, according to numerous experiments conducted in the simulated SDN testbed. The false-positive rate is remains less than 4.3% in many assault scenarios, and the detection delay has been reduced by around 50%. According to the aforementioned data, the framework maintains a comparatively high detection rate as network size and traffic volume increase and is comparatively stable in the face of zero-day assaults. Deep reinforcement learning will therefore enhance the effectiveness and flexibility of SDN-based honeypot systems based on the aforementioned experiments. The design can facilitate the development of a high-performance autonomous and proactive network protection system, according to the research mentioned above.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Aleksandar Popović, Jelena Simić

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





