Adversarially-Trained RoBERTa for Robust Technical Term Recognition in Scientific and Engineering Documents
DOI:
https://doi.org/10.64972/jaat.2024v2.131p3e:29-42Keywords:
Natural Language Processing, Adversarial Training, Technical Term Recognition, Domain Adaptation, Information ExtractionAbstract
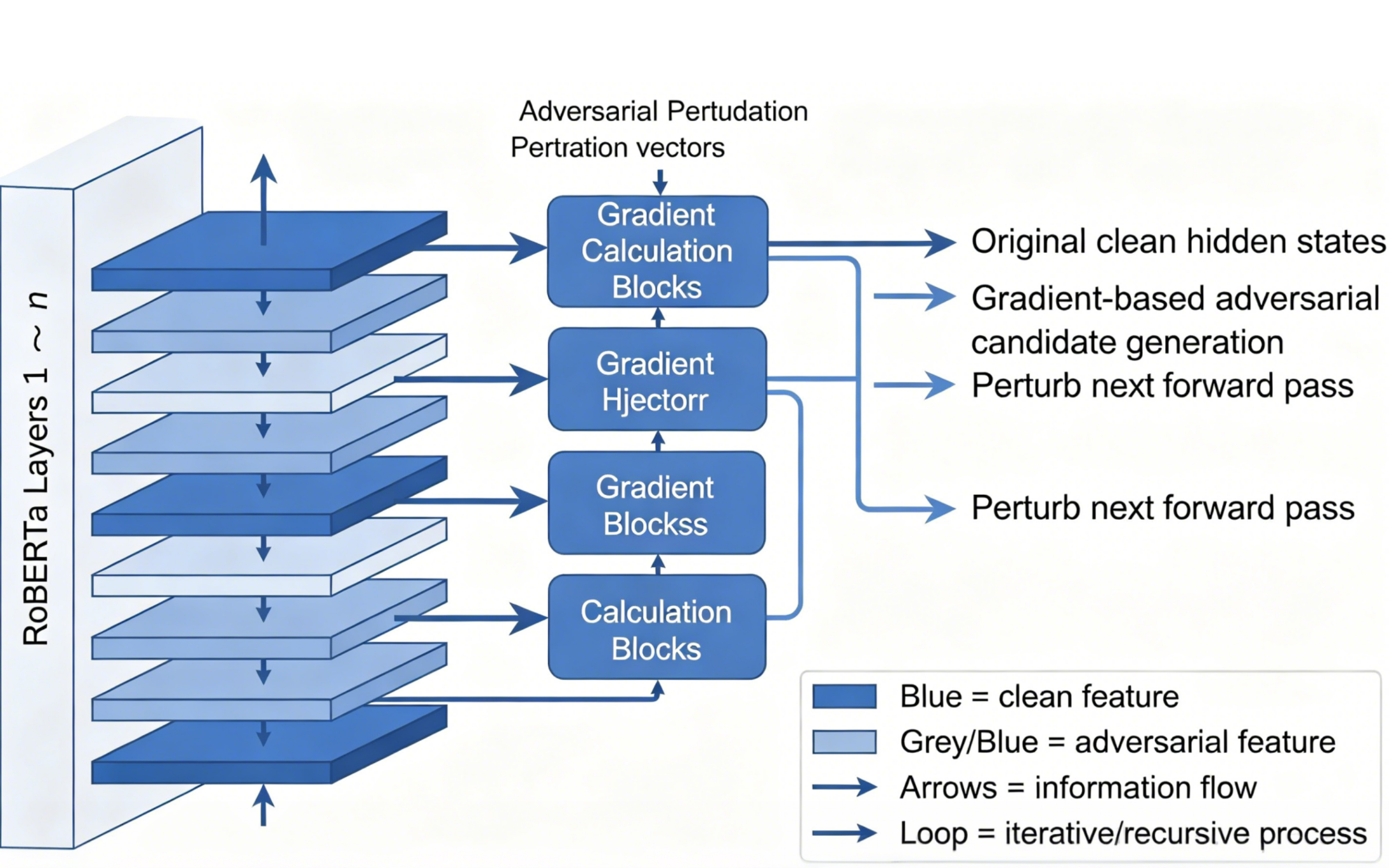
In research and technology, information retrieval and knowledge graph generation are common applications of technical term recognition. In order to solve the issues of term boundary ambiguity and robustness to input perturbations in complex technical corpora, this research suggests an adversarial training method for a domain-adapted RoBERTa model. The aforementioned method optimally combines clean and adversarial feature streams using a joint decoding technique and constructs various tiers of gradient-informed adversarial perturbations in the transformer network. Comprehensive tests were conducted using three heterogeneous datasets containing over 5 million tokens and over 900,000 annotated technical phrases. The findings demonstrate that the adversarially-trained system maintains an accuracy of over 84% during cross-domain transfer, achieves a boundary-level F1 score of 89.3% under synthetic input permutation attacks, and is at least 14.7% higher than the standard RoBERTa model in the presence of strong adversarial noise. Error analysis has decreased false boundary insertions by 60.3% when compared to the baseline model, and ablation investigations demonstrate the synergistic effect of multi-layer perturbation and dual-path decoding. As a result, it is evident that the aforementioned research offers a solid basis for developing a fault-tolerant, high-accuracy automated technological term extraction system for practical application.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Piotr Aleksander Kamiński, Anna Maria Nowicka, Natalia Joanna Dąbrowska, Natalia Woźniak

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





