UNITER-Based Multimodal Extraction Framework for Structured Information Mining in Scientific Literature
DOI:
https://doi.org/10.64972/dea.2026.v5i2.1896d:73-86Keywords:
Multimodal Information Extraction, Scientific Document Analysis, Cross-Modal Alignment, Knowledge MiningAbstract
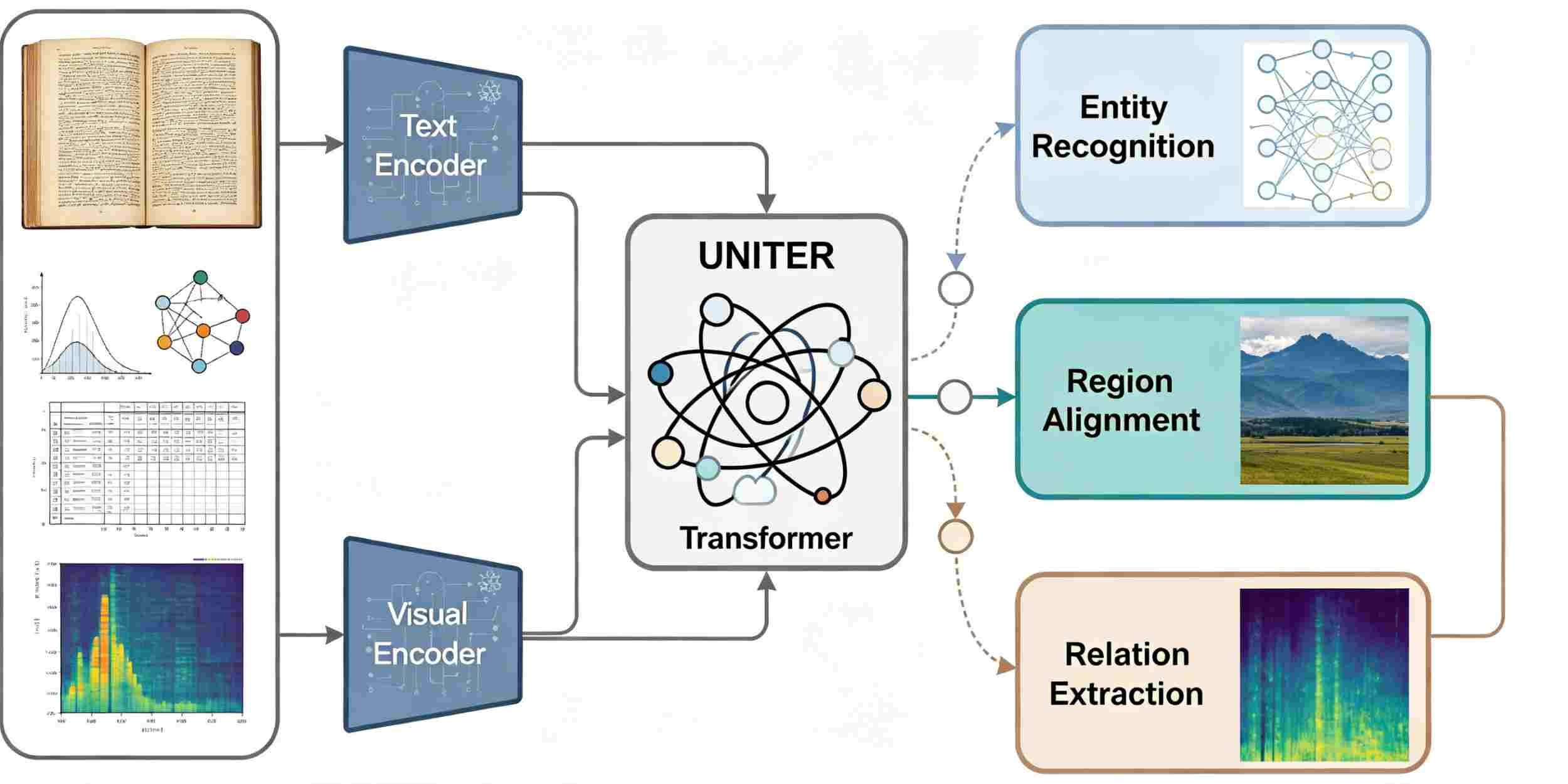
Scientific writing now frequently contains a lot of figures, tables, and other visual aids due to its expanded scope. Based on an enhanced UNITER transformer model, a unified extraction framework has been created in this study to overcome the aforementioned issues. The system is able to extract and align entities and relations from several locations simultaneously, as well as handle the heterogeneity of scientific texts. This system effectively integrates text and visual information through the use of an advanced cross-modal fusion mechanism and adaptive region selection. With over 39,000 papers, several experiments have been conducted on annotated datasets in the fields of biology, materials science, and chemistry. The experimental results showed that these three areas beat the initial baseline model, with F1-scores of 0.856, 0.811, and 0.847, respectively. To improve extraction accuracy, cross-modal attention and spatial region grounding must be included, according to the ablation experiment. The aforementioned error analysis indicates that entity localisation has a robust function and is not hampered by other problems like semantic ambiguity or a complicated annotation structure. The suggested architecture for organised knowledge mining in scientific literature has been confirmed to be workable and expandable based on the aforementioned findings.
Downloads
Published
How to Cite
Issue
Section




