Pedestrian Pavement Crack Detection Method Based on DeepLabv3-DRN Fusion
DOI:
https://doi.org/10.64972/dea.2026.v5i1.1591d:1-14Keywords:
Image Analysis, Semantic Segmentation, Deep Learning, Crack Detection, Pavement Infrastructure, Feature Fusion, Model Robustness, Real-Time ProcessingAbstract
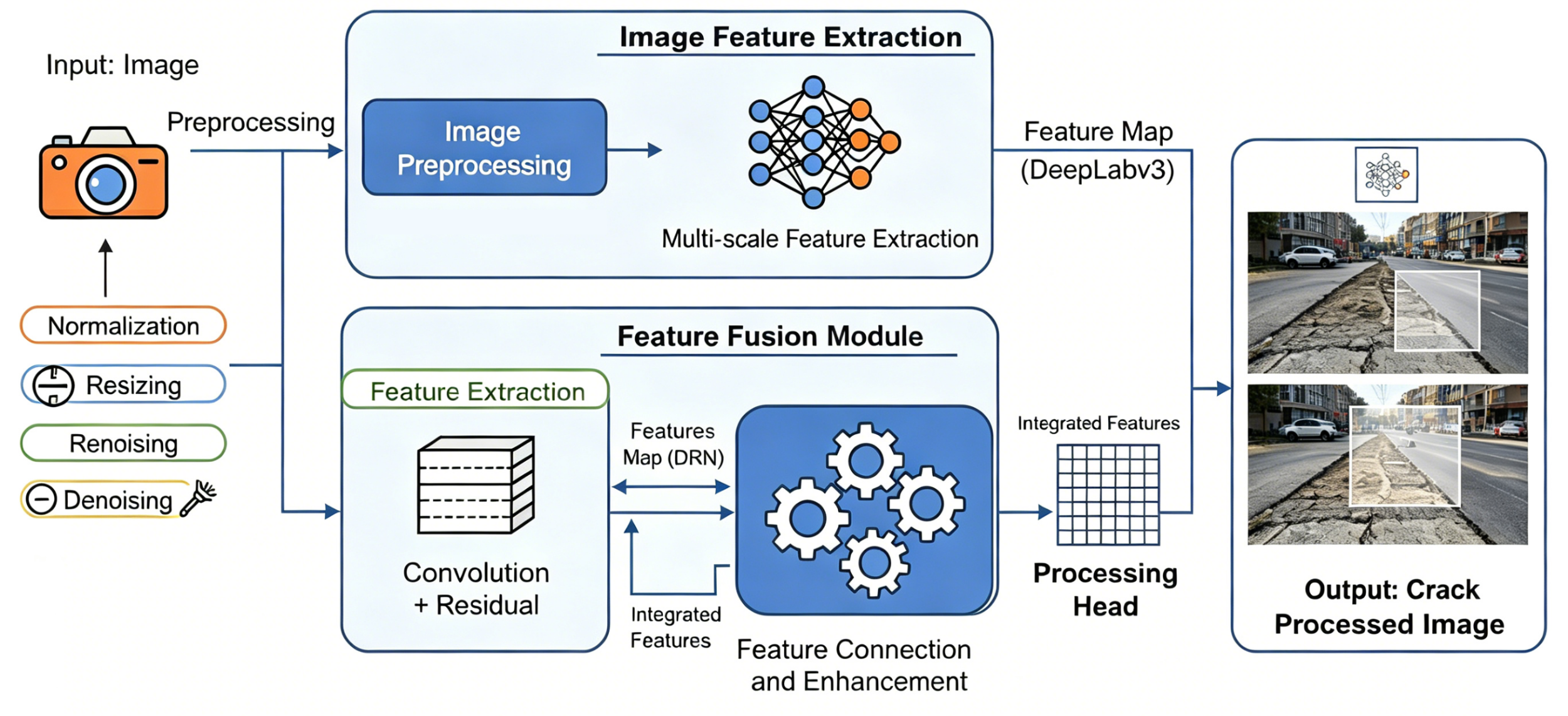
Due to changes in materials and complex environmental factors, previous inspection methods are no longer reliable, and semantic segmentation algorithms have become useful tools for solving the problem of sidewalk crack detection. This paper introduces a new crack segmentation framework that combines DeepLabv3 and the Dilated Residual Network (DRN), using a structured multi-level feature fusion strategy. By integrating local details and broad contextual information through parallel backbone extraction and channel attention modules, various shapes, widths, and visibility of cracks can be effectively identified. In the validation experiments of public and private datasets, over 1,600 labeled pavement images were collected from various cities. The average Intersection over Union (mIoU) of the fusion model is 0.81, which is 3-5% higher than U-Net and DeepLabv3+. On a typical GPU, the inference speed reaches up to 41 frames per second, with minimal memory usage, and the average F1-score exceeds 0.79 across all datasets. Ablation studies show that both feature fusion and enhancement modules are necessary. If they are excluded, the mIoU will drop to 0.72. A detailed examination of the errors indicates that the model reduces false positives in cases of occlusion and background clutter. The above results indicate that the DeepLabv3-DRN fusion framework can improve the accuracy and generalization ability of automatic crack detection in pedestrian pavement environments.
Downloads
Published
How to Cite
Issue
Section




