Automatic Scientific Literature Text Summarization Based on GPT-4
DOI:
https://doi.org/10.64972/jaat.2026v4.108Keywords:
Scientific Summarization, Transformer Models, Domain Adaptation, Factual Consistency, Prompt Engineering, Automatic Text GenerationAbstract
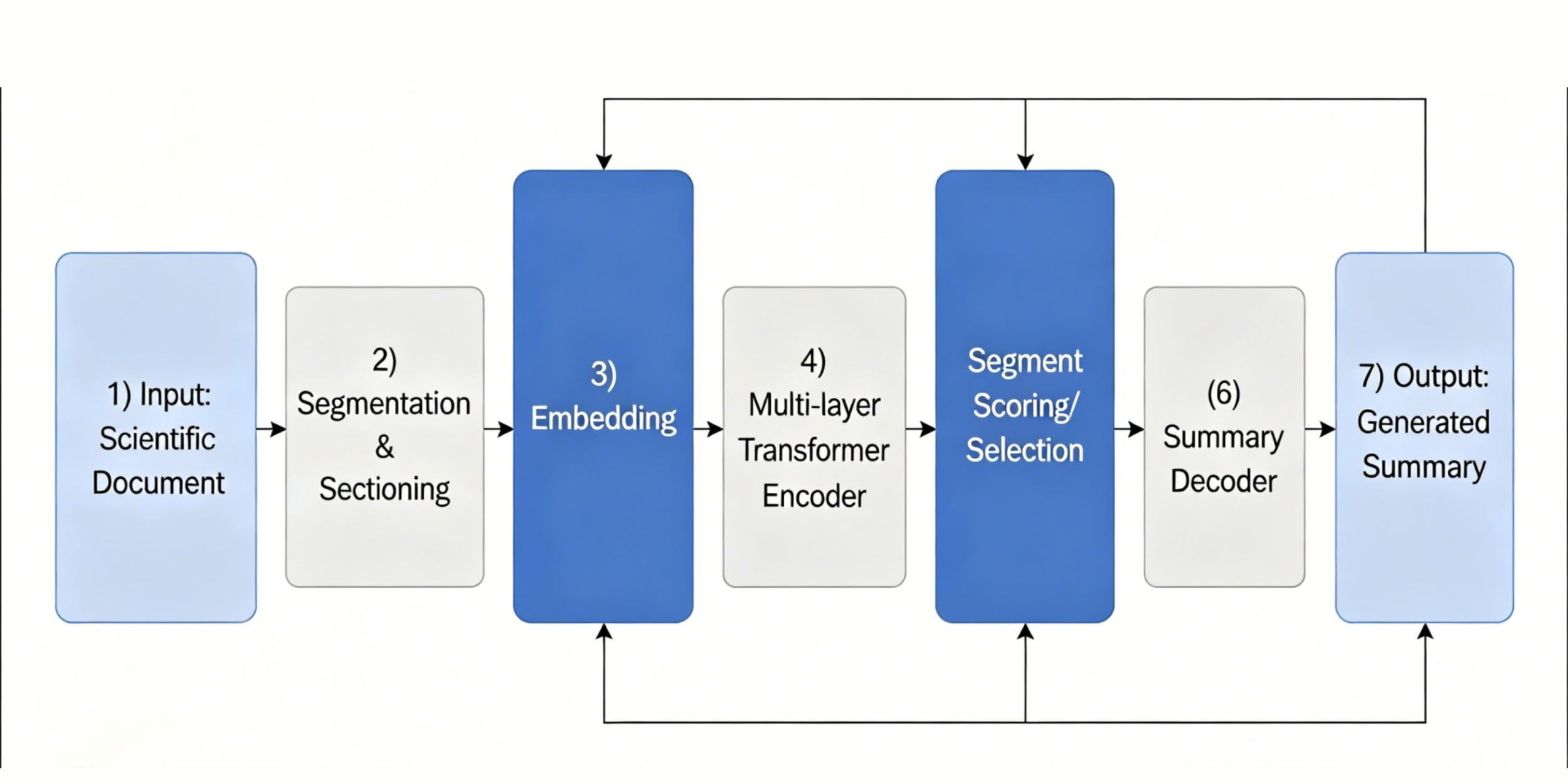
Using advanced transformer-based language models, automatic scientific document summarization has begun to address the information overload problem in the big data era. To summarize English and Chinese academic papers, this paper develops a complete system based on the GPT-4 model. Hierarchical tokenization, paragraph-aware encoding, and gated paragraph scoring are methods by which the new system effectively addresses the discourse and logical differences between different academic papers. Perform domain-adaptive masked language modeling using a two-step training strategy. The model is first trained on specialized terminology, and then fine-tuned with annotated full texts and summaries. Prompt engineering strategies can help create summaries and meet user needs. Many experiments were conducted on benchmark datasets such as arXiv, PubMed, and CSL, using a unified preprocessing pipeline and evaluation protocol. Based on the above results, the ROUGE and BERTScore metrics indicate an improvement in coverage and semantic accuracy. The system improves the accuracy and clarity of the summaries thru robust post-processing and entity normalization. Strict human evaluations also indicate that, compared to leading baseline models, there is an increase in the amount of information and unsupported content. Based on the above findings, the framework demonstrates strong generalization capabilities across many languages and scientific domains. Therefore, it is very suitable for large-scale, high-fidelity literature summarization and knowledge extraction.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Rajesh Joshi, Manoj Iyer, Rakesh Verma, Chunbo Lin

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.





