A Comparative Study on Privacy-Preserving Similarity Search Based on LSH and MinHash Algorithms
DOI:
https://doi.org/10.64972/dea.2025.v4i2.2428d:101-116Keywords:
Information Retrieval, Privacy Preservation, Locality-Sensitive Hashing, MinHash, Similarity SearchAbstract
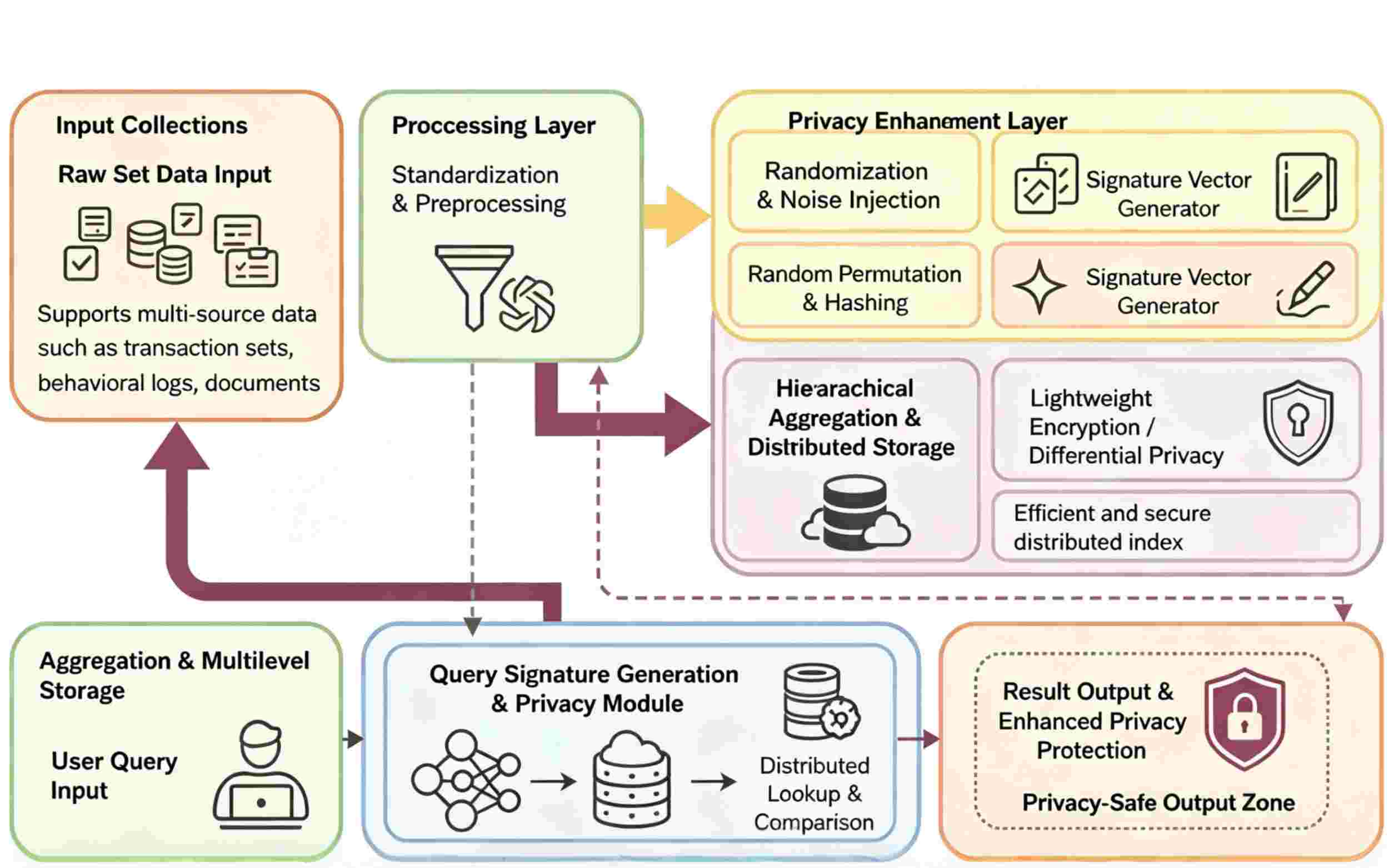
Similarity search is a frequently used approach for comprehensive information management in the modern era. In this research, we compare the effectiveness and privacy-preservation capabilities of MinHash and Locality-Sensitive Hashing (LSH) algorithms for large-scale similarity search under privacy restrictions. This work is divided into three categories: semantic embeddings, large-scale transactional data, and high-dimensional visual characteristics. Both methods are tested under various noise, randomization, and cryptography settings in both a baseline and a privacy-enhanced mode. According to the aforementioned findings, LSH outperforms MinHash for top-k recall and query time in dense feature vector environments, demonstrating an increase in mean average precision of up to 7.5% in the absence of privacy constraints. For sparse and set-based data, MinHash is more reliable and has a comparatively stable accuracy at a lower level of privacy protection when the privacy parameter is increased. According to empirical research, MinHash is 10% more attack-resistant and has a 12% lower information leakage than LSH in adversarial simulations at the same privacy expenditure. It is now possible to identify the appropriate similarity-search algorithms for various data attributes and privacy constraints based on the aforementioned results. Thus, this project will also investigate how to develop useful, private-preserving retrieval technology based on multi-dimensional evaluation and algorithm optimization.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Stjepan Novak, Antonio Matošević

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.




