Unsupervised Keyword Extraction from Technical Papers via Integrated Text Rank and BERT for Enhanced Domain Adaptivity
DOI:
https://doi.org/10.64972/jiic.2026v4.177p10s:123-135Keywords:
Technical Documents, Keyword Extraction, Unsupervised Learning, BERT, Graph-Based Methods, Domain AdaptationAbstract
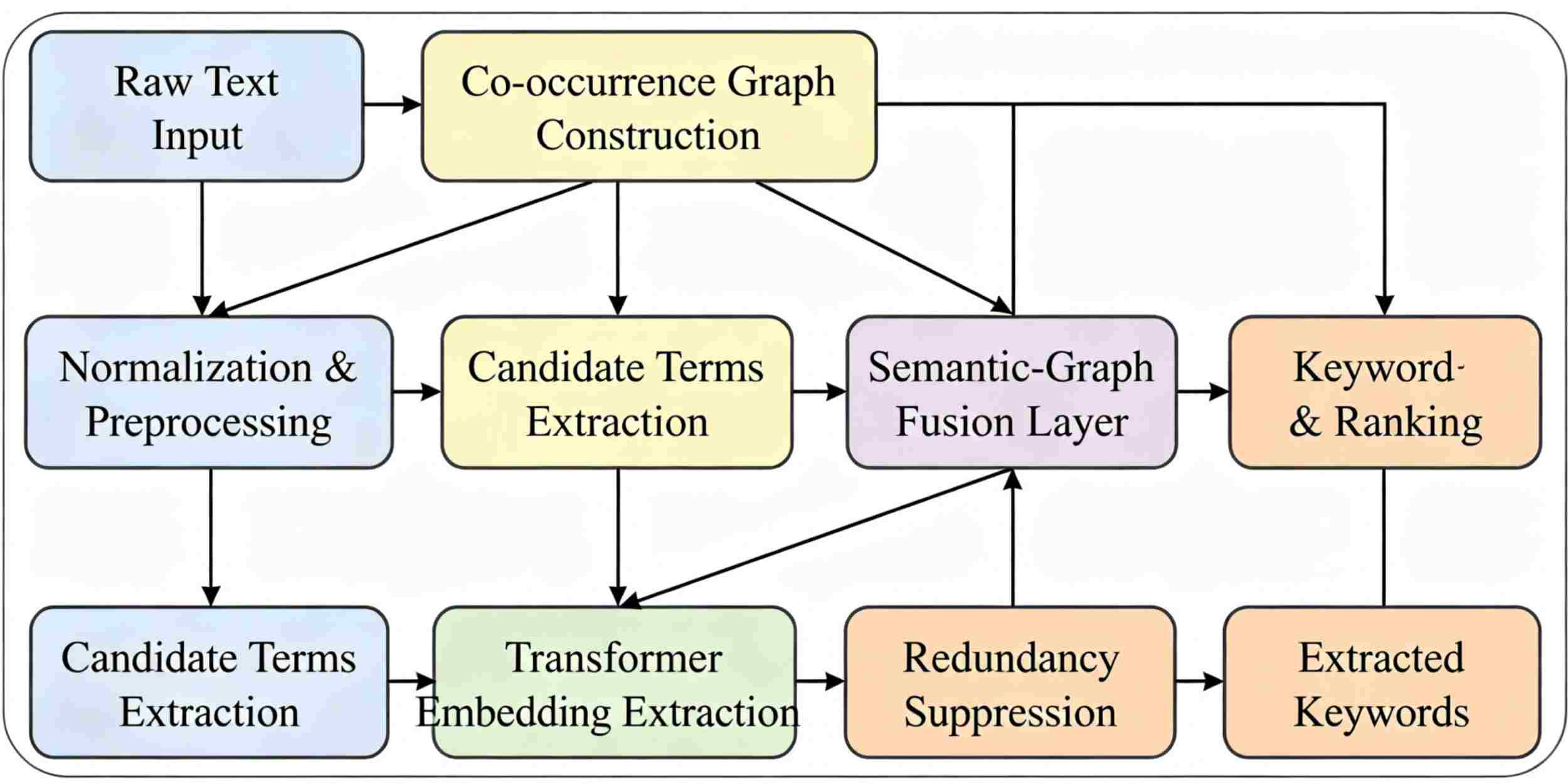
With the increase in scientific and engineering literature, extracting useful information from complex text corpora has become increasingly difficult. To address this need, an unsupervised method employs graph-based text ranking and deep semantic information generated by BERT. This method automatically extracts keywords from technical texts. To some extent, some semantic-based methods can handle changes in document structure while addressing the shortcomings of traditional methods in identifying context-related terms. Describe the topological structure and meaning of the document, as well as the construction of dynamic co-occurrence graphs and the generation of context-sensitive embedding vectors. According to the novel graph embedding fusion technique, candidates are ranked based on their structural prominence and contextual specificity. Comprehensive experiments conducted on benchmark datasets in computational linguistics, medical literature analysis, and engineering patent classification show that this method outperforms traditional models in terms of recall, accuracy, and F1-score. Further cross-domain analysis demonstrates its strong generalization ability and continued good performance under domain transfer and new terminology. The errors revealed actual issues in multilingual and structurally erroneous texts, providing direction for improvement. This paper proposes a feasible method for extracting key terms from technical documents. By quickly leveraging changes in the field of science and technology to improve the accuracy of information.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Marcin Kaczor, Zbigniew Malinowski

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.




