XLNet-based Self-supervised Pretraining Method for Patent Text Classification
DOI:
https://doi.org/10.64972/jiic.2026v4.139p1s:26-38Keywords:
Deep Learning, XLNet, Self-supervised Learning, Patent Classification, Natural Language ProcessingAbstract
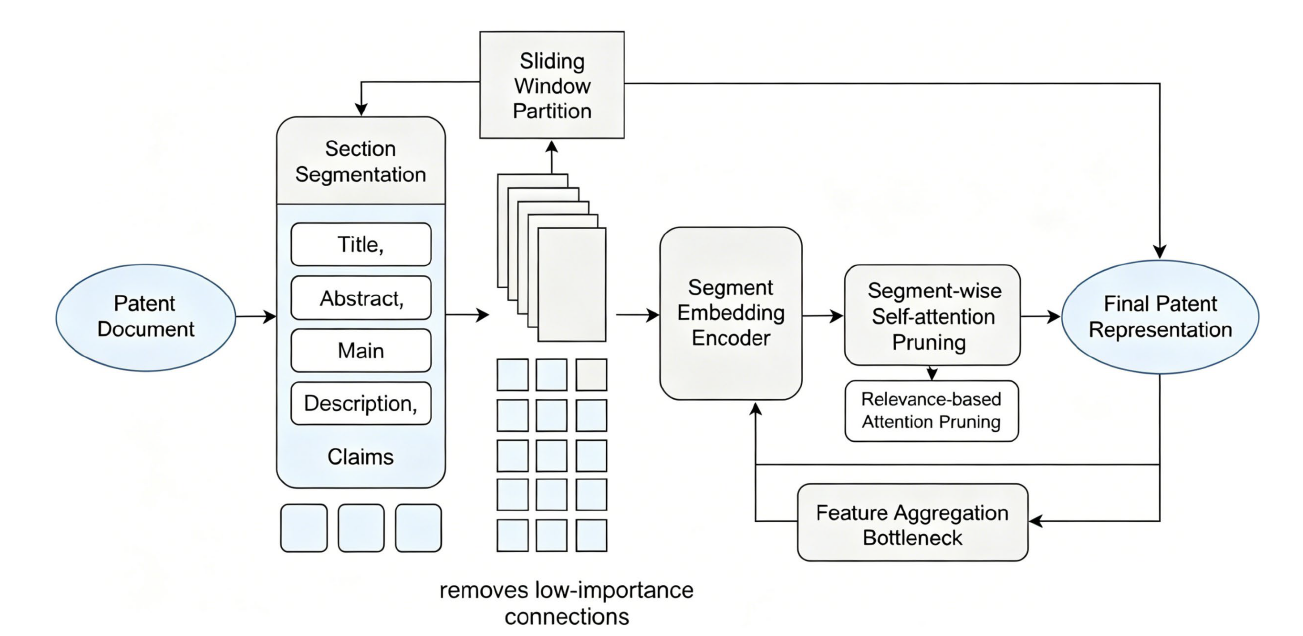
With the sustained growth in global patent filings, the efficient and accurate classification of patent documents has become increasingly important for intellectual property management and technological innovation. This study aims to address the persistent challenges of large-scale data volume, complex document structure, and severe class imbalance present in patent text classification. To this end, we propose a patent classification framework based on a self-supervised XLNet model, custom-built to capture both technical and legal features inherent to patent literature. The model incorporates boundary-aware permutation language modeling and introduces patent-specific auxiliary tasks that jointly enhance intra- and inter-segment representation. Experiments are conducted on a comprehensive benchmark dataset containing 3.6 million patent documents across 134 primary categories and 880 subclasses. The proposed approach achieves a micro-averaged accuracy of 87.0% and a micro-F1 score of 85.6% on the test set, outperforming baseline models, including BERT and conventional deep learning architectures, especially in long-text scenarios and for rare subclasses. The results confirm the effectiveness of targeted self-supervised learning and class-imbalance mitigation strategies. Overall, this work demonstrates a scalable and robust method for patent document classification, offering practical value for industrial applications and future research in specialized text analytics.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Filip Lis, Izabela Rutkowski

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.




